Are test developers (that includes me, the blog dictator) increasingly overfactoring intelligence test batteries?
According to an article by Frazier and Youngstrom "in press" in the prestigious journal Intelligence, contemporary test developers (and their publishing companies) "are not adequately measuring the number of factors they are purported to measure." Below is the reference citation and abstract (with a link to the article).
According the Frazier and Youngstrom, the purpose of their investigation was: "The present paper proposes that several forces have influenced this trend including: increasingly complex theories of intelligence (Carroll, 1993; Vernon, 1950), commercial test publishers' desire to provide assessment instruments with greater interpretive value to clinicians, publishers' desire to include minor ability factors that may only be of interest to researchers, and heavy reliance on liberal statistical criteria for determining the number of factors measured by a test. The latter hypothesis is evaluated empirically in the present study by comparing several statistical criteria for determining the number of factors present in current and historically relevant cognitive ability batteries."
As a coauthor of one of the batteries (WJ III) analyzed in this study and, in particular, the battery that measures the largest number of factors in their investigation, I feel compelled to respond to portions of this manuscript. Thus, readers should read the original article and then review my comments, fully recognizing that I have a commercial conflict of interest.
Before I present the major conclusions of the article and provide select responses, I'd like to first state that, in many respects, I think this is a well done article. Regardless of the extent to which I agree/disagree with Frazier and Youngstrom, the introduction is worth reading for at least two reasons.
- The article provides a nice (brief) overview of development of psychometric intelligence theories from Spearman through early hierarchical theories (Vernon) to contemporary Carroll and Cattell-Horn Gf-Gc (the later two now often referred to as Cattell-Horn-Carroll [CHC] theory).
- In addition, for individuals looking for a brief description and synopsis of the major statistical approaches to determining the number of factors to retain in factor analytic studies, pages 3-6 are recommended.
Frazier, T. & Youngstrom, E. (2006, in press). Historical increase in the number of factors measured by commercial tests of cognitive ability: Are we overfactoring? Intelligence.
Abstract
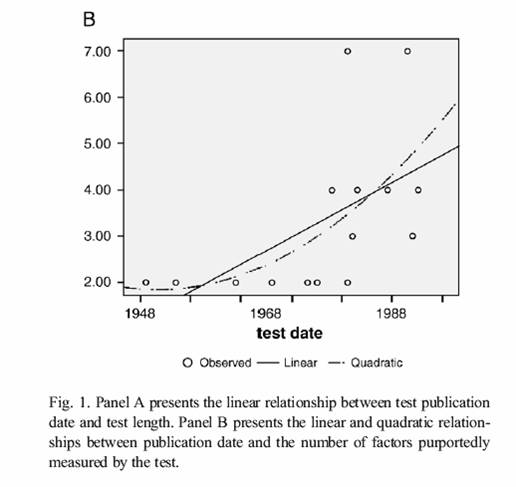
- A historical increase in the number of factors purportedly measured by commercial tests of cognitive ability may result from four distinct pressures including: increasingly complex models of intelligence, test publishers' desires to provide clinically useful assessment instruments with greater interpretive value, test publishers' desires to include minor factors that may be of interest to researchers (but are not clinically useful), and liberal statistical criteria for determining the factor structure of tests. The present study examined the number of factors measured by several historically relevant and currently employed commercial tests of cognitive abilities using statistical criteria derived from principal components analyses, and exploratory and confirmatory factor analyses. Two infrequently used statistical criteria, that have been shown to accurately recover the number of factors in a data set, Horn's parallel analysis (HPA) and Minimum Average Partial (MAP) analysis, served as gold-standard criteria. As expected, there were significant increases over time in the number of factors purportedly measured by cognitive ability tests (r=.56, p=.030). Results also indicated significant recent increases in the overfactoring of cognitive ability tests. Developers of future cognitive assessment batteries may wish to increase the lengths of the batteries in order to more adequately measure additional factors. Alternatively, clinicians interested in briefer assessment strategies may benefit from short batteries that reliably assess general intellectual ability.
Additional comments/conclusions by the authors (followed by my comments/responses)
Frazier/Youngstrom comment: The extensive use of cognitive ability batteries in psychological assessment, an increased market for psychological assessments in general, a desire to create tests that are marketable to both clinicians and researchers, and the desire to increase the reliability of IQ measures may create a pressure on publishers to market ability tests that measure everything that other tests measure and more. This, in turn, forces other ability test publishers to try to keep pace.
- McGrew comment/response: First, I will not attempt to comment on the "desires/pressures" of test developers/publishers of the other major intelligence batteries included in their analyses (Wechsler batteries, SB-IV, K-ABC, DAS). I restrict my comments to my experiences with the WJ-R and WJ III.
- As a coauthor of the WJ III, and the primary data analyst for the WJ-R, I personally can vouch for the fact that there was no pressure exerted by the test publisher, nor we as co-authors, to measure more factors for the sake of just measuring more. As articulated clearly in the original WJ-R technical manual (McGrew, Werder & Woodcock, 1991), and subsequently summarized in the WJ III technical manual (McGrew & Woodcock, 2001), the driving force behind the number of factors was theory-driven, with the input of two of the most prominent psychometric intelligence theorists and factor analysts....John Horn and Jack Carroll (click here, here.) Both Horn and Carroll where intimately involved in the design and review of the factor results of the WJ-R and WJ III norm data. The driving "desire/pressure" during the revision of the WJ-R and WJ III was to validly measure, within practical constraints, the major features of the broad CHC/Gf-Gc abilities that are well established from decades of research (see Carroll's 1993 seminal work, click here, here). For additional information re: the involvement of Horn and Carroll in these deliberations, read the relevant sections of McGrew's (that be me) on-line version of CHC Theory: Past, Present, Future. If there was an underlying driving "pressure", it was to narrow the intelligence theory-practice gap.
Frazier/Youngstrom comment: Several important findings emerged from the present study. As predicted, commercial ability tests have become increasingly complex. While the length of these tests has risen only moderately, the number of factors purportedly measured by these tests has risen substantially, possibly even exponentially. It should be noted, however, that the possibility of an exponential increase in the number of factors purportedly measured may be due to inclusion of two outliers, the WJ-R and WJ-III. Possibly even more convincingly, the ratio of test length to factors purported has decreased dramatically. These trends suggest that test authors may be positing additional factors without including a sufficient number of subtests to measure these factors. When more accurate, recommended, statistical criteria were examined commercial ability tests were found to be substantially overfactored.
- McGrew comment/response: My comment is primarily one of clarification for readers. Frazier and Youngstrom's statement that the ratio of test length to factors has decreased may be relevant to the other batteries analyzed, but is NOT true for the WJ-R and WJ III. The broad CHC factors measured by the WJ III are all represented by at least 3 or more test indicators, a commonly accepted criterion for proper identification of factors. Frazier and Youngstrom (and readers of their article) may find it informative to note that in Jack Carroll's final publication (The higher-stratum structure of cognitive abilities: Current evidence supports g and about ten broad factors. In Helmuth Nyborg (Ed.), The scientific study of general intelligence: Tribute to Arthur R. Jensen. Elsevier Science/Pergamon Press.-click here to access pre-pub copy of Carroll's chapter), Carroll stated that the WJ-R battery (which, when compared to the WJ III, has a lower test-factor ratio) was a "sufficient" set of data "for drawing conclusions about the higher-stratum structure of cognitive abilities." In describing the WJ-R dataset, he stated that "It is a dataset that was designed to test factorial structure only at a second or higher stratum, as suggested by Carroll (1993, p. 579), in that it has sufficient test variables to define several second-stratum factors, as well as the single third- stratum factor, but not necessarily any first-stratum factors." Jack Carroll is no slouch when it comes to the application of factor analysis methods. In fact, he is generally considered as one of the masters of the "art and science" of factor analysis and his contributions of the use of factor analysis methods to the study of cognitive abilities is well known (I recommend folks to read Chapter 3 in Carroll's seminal treatise on the factor structure of human cognitive abilities--"Chapter 3: Survey and Analysis of Correlational and Factor Analytic Research on Cognitive Abilities: Methodology). Frazier and Youngstrom place all of their eggs primarily in the "science" of factor analysis (emphasis on statistical tests). There is an "art" to the practice of factor analysis, something that is missing from the raw empirical approach to their investigation.
Frazier/Youngstrom comment: Results of the present study also suggest that overfactoring of ability tests may be worsening, as the discrepancy between the purported number of factors and the number indicated by MAP and HPA has risen over time and the ratio of subtests to factors purported has decreased substantially as well. While commercial pressures and increasingly complex models of human cognitive abilities are likely contributing to these recent increases, these explanations were not investigated in the present study.
- McGrew comment/response: Where's the beef/data that supports the conclusion that "commercial pressures...are likely contributing to these recent increases?" In the absence of data, such a statement is inappropriate. Yes, increasingly complex models of human cognitive abilities are contributing to batteries that measure more abilities. Science is a process of improving our state of knowledge via the accumulation of evidence over time. The most solid empirical evidence supports a model of intelligence (CHC or Gf-Gc theory) that includes 7-9 broad stratum II abilities. Shouldn't assessment technology stay abreast of contemporary theory? I think the answer should be "yes." Since the authors state that "these explanations were not investigated in the present study" they should have refrained from their "commercial pressures" statement. I'm a bit surprised that such a statement, devoid of presented evidence, survived the editorial process of the journal.
Frazier/Youngstrom comment: Rather, evaluation centered on the hypothesis that test developers have been determining test structure using liberal, and often inaccurate, statistical criteria. This hypothesis was supported.."
- McGrew comment/response: Aside from the failure to recognize the true art and science of the proper application of factor analysis, Frazier and Youngstrom commit a sin that is often committed by individuals (I'm not saying this is true of these two individuals) who become enamored by the magic of quantitative methods (myself included, during my early years...until the likes of John Horn, Jack McArdle, and Jack Horn personally tutored me on the limitations of any single quantitative method, like factor analysis). Briefly, factor analysis is an internal validity method. It can only evaluate the internal structural evidence of an intelligence battery. When I was a factor analytic neophyte, I was troubled by the inability to clearly differentiate (with either exploratory or confirmatory factor methods) reading and writing abilities (Grw) from verbal/crystallized (Gc) abilities. I thought the magic of factor analysis should show these as distinct factors. Both Horn and McArdle gently jolted my "factor analysis must be right" schema by reminding me that (and I'm paraphrasing from memory) "Kevin...factor analysis can only tell you so much about abilities. Often you must look outside of factor analysis, beyond the internal validity findings, to completely understand the totality of evidence that provides support for the differentiation of highly correlated abilities." In particular, Horn and McArdle urged me to examine growth curves for highly correlated abilities that could not be differentiated vis-à-vis factor analysis methods. When I examined the growth curves for Grw and Gc in the WJ-R data, I had an epiphany (note...click here for a report that includes curves for all WJ III tests....note, in particular, the differences between the reading/writing (Grw) and verbal (Gc) tests....tests that often "clump" together in factor analysis). They were correct. Although EFA and CFA could not clearly differentiate these factors, the developmental growth curves for Grw and Gc where dramatically different...so different that it would be hard to conclude that they are the same constructs. Long story short...Frazier and Youngstrom fail to recognize, which they could have in their discussion/limitations section, that construct validity is based on the totality of multiple sources of validity evidence. Internal structural validity evidence is only one form...albeit one of the easier ones to examine for intelligence batteries given the ease of factor analysis these days. As articulated in the Joint Test Standards, and nicely summarized by Horn and others, aside from structural/internal (factor analysis) evidence, evidence for constructs (and purported measures of the constructs) must also come from developmental, heritability, differential outcome prediction, and neurocognitive evidence. Only when all forms evidence are considered can one make a proper appraisal of the validity of the constructs measured by a theoretically-based intelligence battery. For those wanting additional information, click here (you will be taken to a discussion of the different forms of validity evidence as Dawn Flanagan and I discussed in our book, the Intelligence Test Desk Reference.)
I could go on and on with more points and counterpoints, but I shall stop here. I would urge readers to read this important article and integrate the points above when forming opinions regarding the accuracy/appropriateness of the author’s conclusions, particularly with regard to the WJ-R and WJ-III batteries. Also, consulting the WJ-R and WJ-III technical manuals, where multiple sources of validity evidence (internal and external) are presented to support the factor structure of the batteries are presented, is strongly recommended.
Technorati Tags:
psychology,
educational psychology,
neuropsychology,
school psychology,
cognition,
cognitive,
IQ,
IQ testing,
intelligence,
factor analysis,
psychological tests,
WJ-R,
WJ III,
Woodcock-Johnson,
Wechsler,
SB-IV,
K-ABCpowered by performancing firefox